
|
I am currently working as a Research Scientist at KnowDis AI. I recently completed my Ph.D. at Indian Institute of Technology Delhi (IIT Delhi), India, where I focused on solving cutting-edge problems in Extreme Multi-label Learning (XML) with tangible real-world applications. I worked with Dr. Manik Varma, Dr. Sumeet Agarwal, and Dr. Purushottam Kar on deep learning for extreme multi-label classification. I had previously worked with Dr. C Krishna Mohan on scalable visual computing applications as part of my Masters thesis. Our recent work DeepXML not only provides a uniform framework to analyze and improve existing deep extreme classifiers but it also yielded a family of deep extreme classification algorithms such as Astec, DECAF, GalaXC, ECLARE, MUFIN, SiameseXML, NGAME, DEXA, and PRIME. These algorithms have found applications in various real-world applications including query recommendation and ads where it is benefitting millions of users and small buisnesses. |
|
| |
|
abstract /
bibtex /
pdf /
code
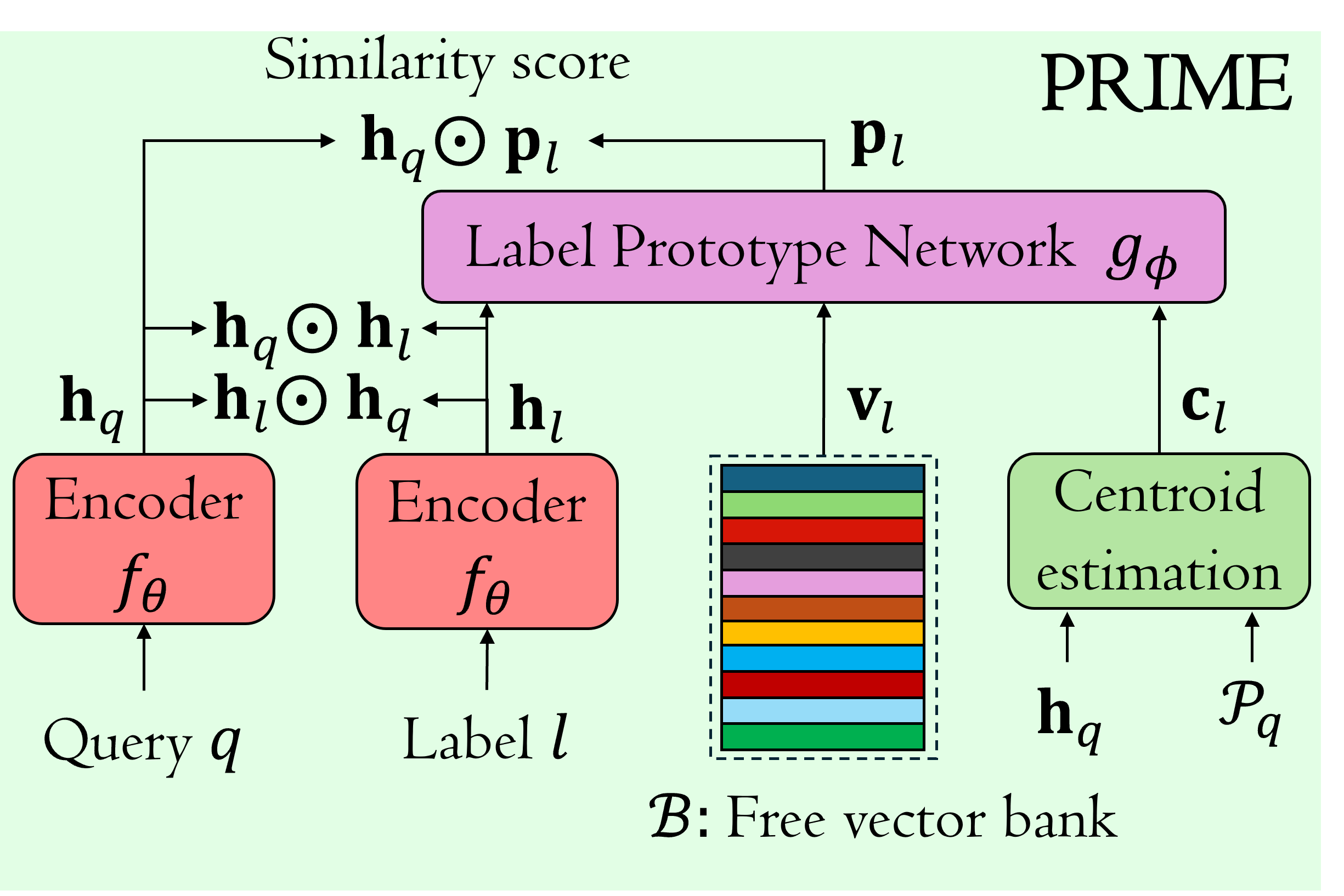
Extreme Multi-label Classification (XMC) methods predict relevant labels for a given query in an extremely large label space. Recent works in XMC address this problem using deep encoders that project text descriptions to an embedding space suitable for recovering the closest labels. However, learning deep models can be computationally expensive in large output spaces, resulting in a trade-off between high performing brute-force approaches and efficient solutions. In this paper, we propose PRIME, a XMC method that employs a novel prototypical contrastive learning technique to reconcile efficiency and performance surpassing brute-force approaches. We frame XMC as a data-to-prototype prediction task where label prototypes aggregate information from related queries. More precisely, we use a shallow transformer encoder that we coin as Label Prototype Network, which enriches label representations by aggregating text-based embeddings, label centroids and learnable free vectors. We jointly train a deep encoder and the Label Prototype Network using an adaptive triplet loss objective that better adapts to the high granularity and ambiguity of extreme label spaces. PRIME achieves state-of-the-art results in several public benchmarks of different sizes and domains, while keeping the model efficient. |
|
abstract /
bibtex /
pdf /
code
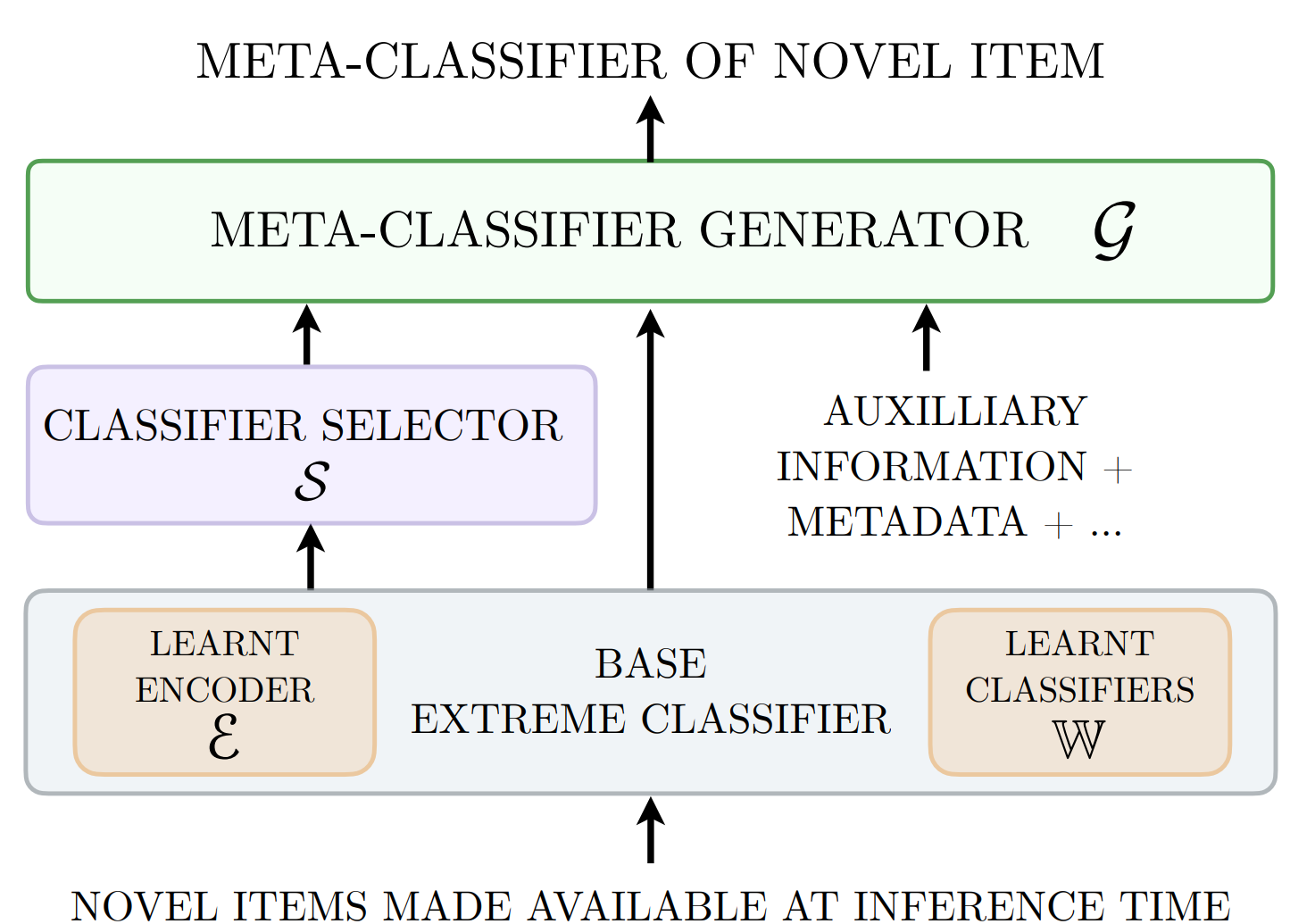
We develop accurate and efficient solutions for large-scale retrieval tasks where novel (zero-shot) items can arrive continuously at a rapid pace. Conventional Siamese-style approaches embed both queries and items through a small encoder and retrieve the items lying closest to the query. While this approach allows efficient addition and retrieval of novel items, the small encoder lacks sufficient capacity for the necessary world knowledge in complex retrieval tasks. The extreme classification approaches have addressed this by learning a separate classifier for each item observed in the training set which significantly increases the representation capacity of the model. Such classifiers outperform Siamese approaches on observed items, but cannot be trained for novel items due to data and latency constraints. To bridge these gaps, this paper develops: (1) A new algorithmic framework, EMMETT, which efficiently synthesizes classifiers on-the-fly for novel items, by relying on the readily available classifiers for observed items; (2) A new algorithm, IRENE, which is a simple and effective instance of EMMETT that is specifically suited for large-scale deployments, and (3) A new theoretical framework for analyzing the generalization performance in large-scale zero-shot retrieval which guides our algorithm and training related design decisions. Comprehensive experiments are conducted on a wide range of retrieval tasks which demonstrate that IRENE improves the zero-shot retrieval accuracy by up to 15% points in Recall@10 when added on top of leading encoders. Additionally, on an online A/B test in a large-scale ad retrieval task in a major search engine, IRENE improved the ad click-through rate by 4.2%. Lastly, we validate our design choices through extensive ablative experiments. |
|
abstract /
bibtex /
pdf /
code
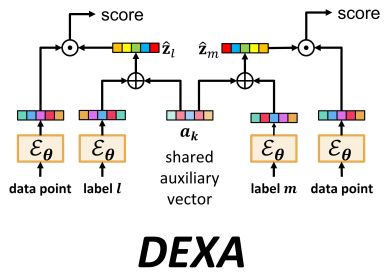
The task of annotating a data point with labels most relevant to it from a large universe of labels is referred to as Extreme Classification (XC). State-of-the-art XC methods have applications in ranking, recommendation, and tagging and mostly employ a combination architecture comprised of a deep encoder and a high-capacity classifier. These two components are often trained in a modular fashion to conserve compute. This paper shows that in XC settings where data paucity and semantic gap issues abound, this can lead to suboptimal encoder training which negatively affects the performance of the overall architecture. The paper then proposes a lightweight alternative DEXA that augments encoder training with auxiliary parameters. Incorporating DEXA into existing XC architectures requires minimal modifications and the method can scale to datasets with 40 million labels and offer predictions that are up to 6% and 15% more accurate than embeddings offered by existing deep XC methods on benchmark and proprietary datasets, respectively. The paper also analyzes DEXA theoretically and shows that it offers provably superior encoder training than existing Siamese training strategies in certain realizable settings. |
|
abstract /
bibtex /
pdf /
code
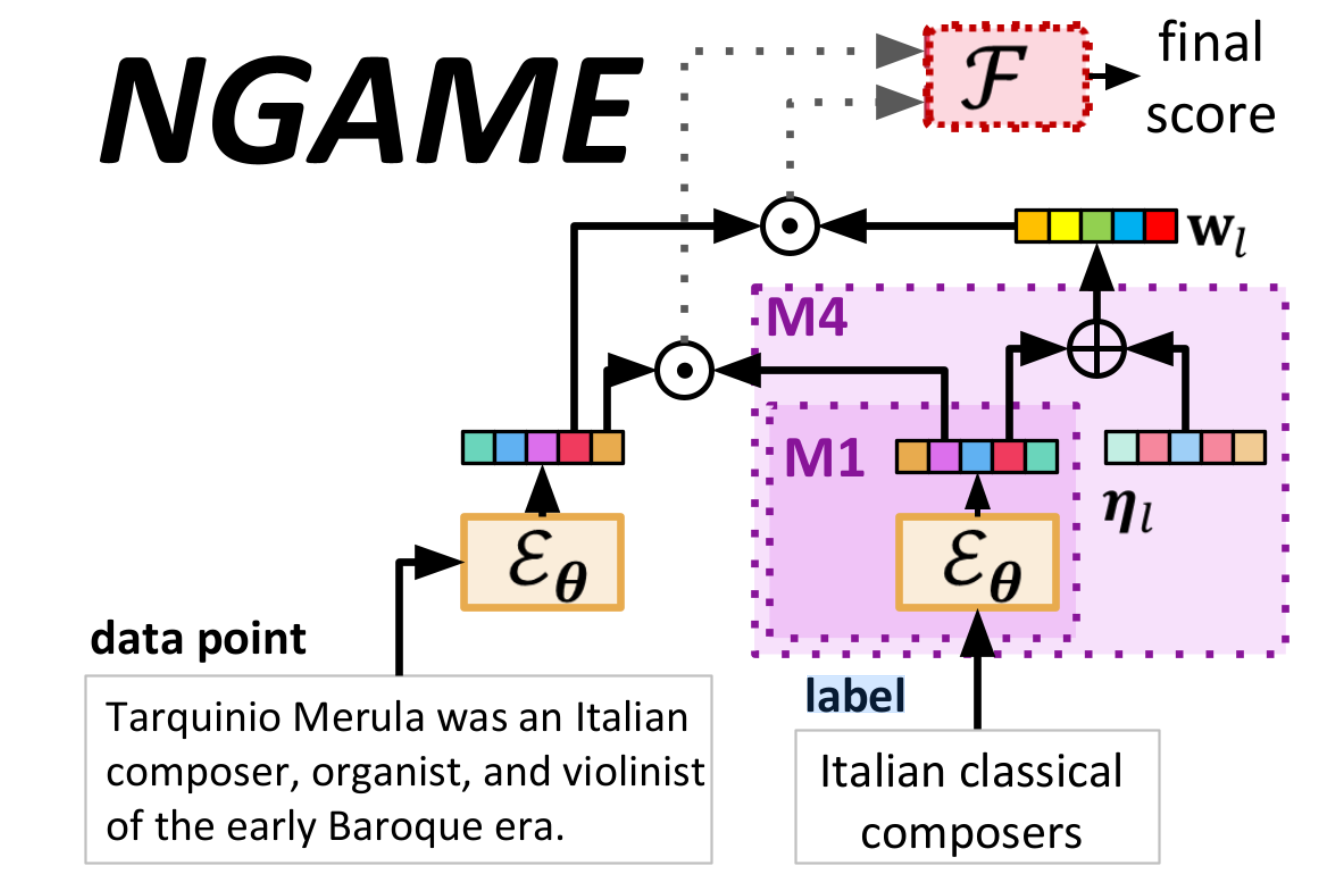
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods, allowing them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper notices that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates. |
|
abstract /
bibtex /
pdf /
code
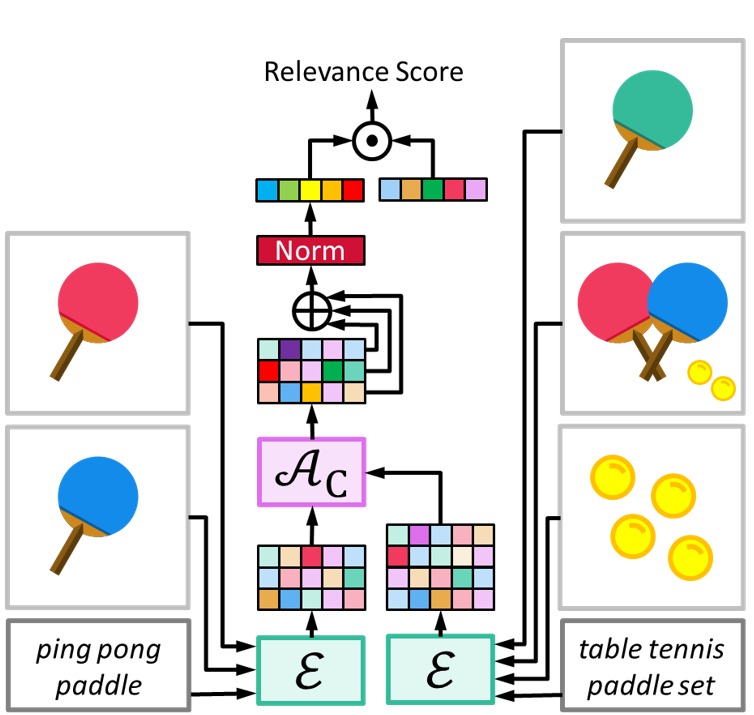
This paper develops the MUFIN technique for extreme classification (XC) tasks with millions of labels where data-points and labels are endowed with visual and textual descriptors. Applications of MUFIN to product-to-product recommendation and bid query prediction over several millions of products are presented. Contemporary multi-modal methods frequently rely on purely embedding-based methods. On the other hand, XC methods utilize classifier architectures to offer superior accuracies than embedding-only methods but mostly focus on text-based categorization tasks. MUFIN bridges this gap by reformulating multi-modal categorization as an XC problem with several millions of labels. This presents the twin challenges of developing multi-modal architectures that can offer embeddings sufficiently expressive to allow accurate categorization over millions of labels; and training and inference routines that scale logarithmically in the number of labels. MUFIN develops an architecture based on cross-modal attention and trains it in a modular fashion using pre-training and positive and negative mining. A novel product-to-product recommendation dataset MM-AmazonTitles-300K containing over 300K products was curated from publicly available amazon.com listings with each product endowed with a title and multiple images. On the MM-AmazonTitles-300K and Polyvore datasets, and a dataset with over 4 million labels curated from click logs of the Bing search engine, MUFIN offered at least 3% higher accuracy than leading text-based, image-based and multi-modal techniques. |
|
abstract /
bibtex /
pdf /
code
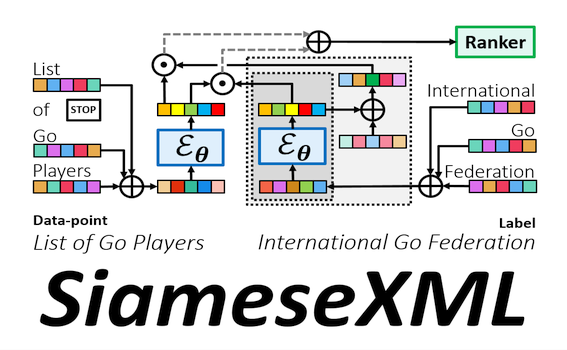
Deep extreme multi-label learning (XML) requires training deep architectures that can tag a data point with its most relevant subset of labels from an extremely large label set. XML applications such as ad and product recommendation involve labels rarely seen during training but which nevertheless hold the key to recommendations that delight users. Effective utilization of label metadata and high quality predictions for rare labels at the scale of millions of labels are thus key challenges in contemporary XML research. To address these, this paper develops the SiameseXML framework based on a novel probabilistic model that naturally motivates a modular approach melding Siamese architectures with high-capacity extreme classifiers, and a training pipeline that effortlessly scales to tasks with 100 million labels. SiameseXML offers predictions 2-13% more accurate than leading XML methods on public benchmark datasets, as well as in live A/B tests on the Bing search engine, it offers significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. |
|
abstract /
bibtex /
pdf /
code
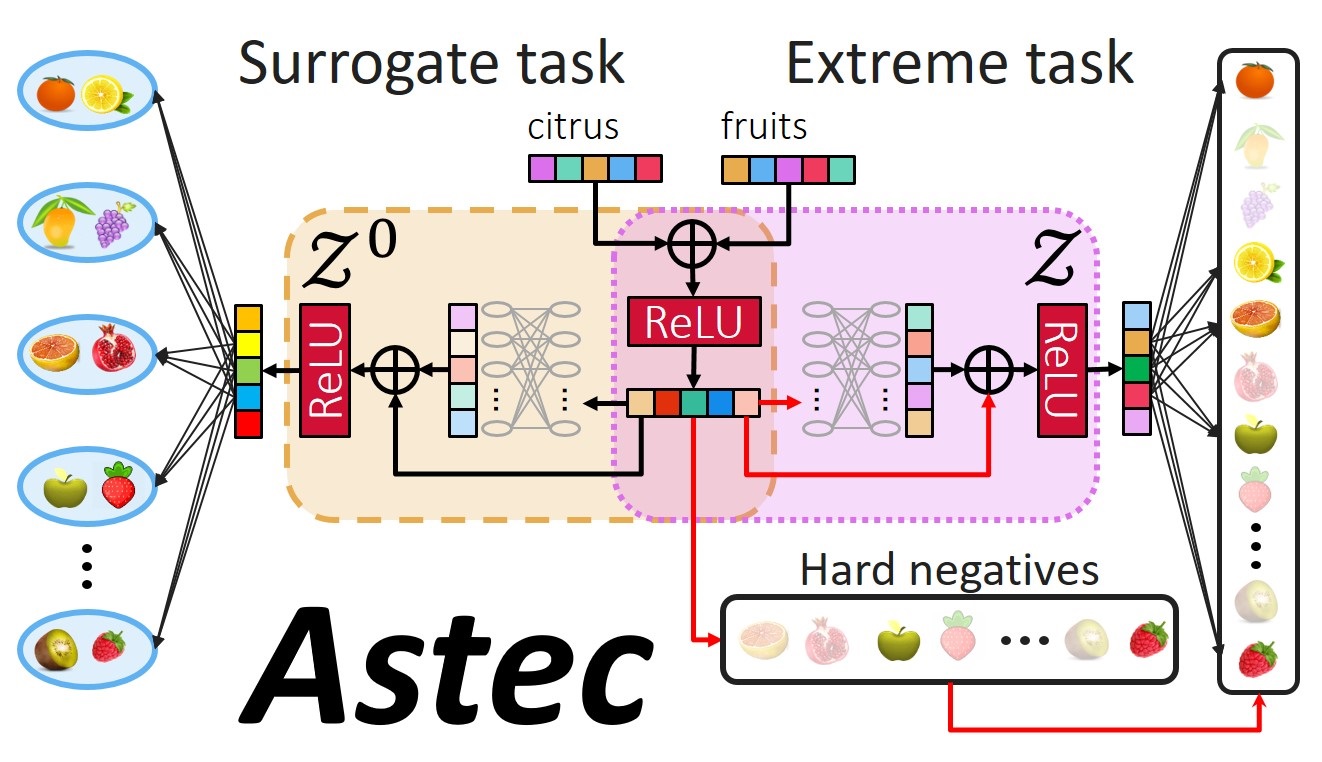
Scalability and accuracy are well recognized challenges in deep extreme multi-label learning where the objective is to train architectures for automatically annotating a data point with the most relevant subset of labels from an extremely large label set. This paper develops the DeepXML framework that addresses these challenges by decomposing the deep extreme multi-label task into four simpler sub-tasks each of which can be trained accurately and efficiently. Choosing different components for the four sub-tasks allows DeepXML to generate a family of algorithms with varying trade-offs between accuracy and scalability. In particular, DeepXML yields the Astec algorithm that could be 2-12% more accurate and 5-30x faster to train than leading deep extreme classifiers on publically available short text datasets. Astec could also efficiently train on Bing short text datasets containing up to 62 million labels while making predictions for billions of users and data points per day on commodity hardware. This allowed Astec to be deployed on the Bing search engine for a number of short text applications ranging from matching user queries to advertiser bid phrases to showing personalized ads where it yielded significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. |
|
abstract /
bibtex /
pdf /
code
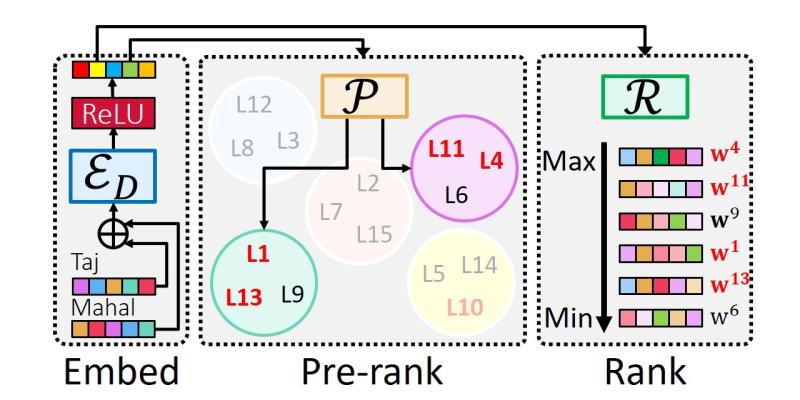
Extreme multi-label classification (XML) involves tagging a data point with its most relevant subset of labels from an extremely large label set, with several applications such as product-to-product recommendation with millions of products. Although leading XML algorithms scale to millions of labels, they largely ignore label metadata such as textual descriptions of the labels. On the other hand, classical techniques that can utilize label metadata via representation learning using deep networks struggle in extreme settings. This paper develops the DECAF algorithm that addresses these challenges by learning models enriched by label metadata that jointly learn model parameters and feature representations using deep networks and offer accurate classification at the scale of millions of labels. DECAF makes specific contributions to model architecture design, initialization, and training, enabling it to offer up to 2-6% more accurate prediction than leading extreme classifiers on publicly available benchmark product-to-product recommendation datasets, such as LF-AmazonTitles-1.3M. At the same time, DECAF was found to be up to 22x faster at inference than leading deep extreme classifiers, which makes it suitable for real-time applications that require predictions within a few milliseconds. |

|
abstract /
bibtex /
pdf /
code
The objective in extreme multi-label learning is to build classifiers that can annotate a data point with the subset of relevant labels from an extremely large label set. Extreme classification has, thus far, only been studied in the context of predicting labels for novel test points. This paper formulates the extreme classification problem when predictions need to be made on training points with partially revealed labels. This allows the reformulation of warm-start tagging, ranking and recommendation problems as extreme multi-label learning with each item to be ranked/recommended being mapped onto a separate label. The SwiftXML algorithm is developed to tackle such warm-start applications by leveraging label features. SwiftXML improves upon the state-of-the-art tree based extreme classifiers by partitioning tree nodes using two hyperplanes learnt jointly in the label and data point feature spaces. Optimization is carried out via an alternating minimization algorithm allowing SwiftXML to efficiently scale to large problems. Experiments on multiple benchmark tasks, including tagging on Wikipedia and item-to-item recommendation on Amazon, reveal that SwiftXML's predictions can be up to 14 % more accurate as compared to leading extreme classifiers. SwiftXML also demonstrates the benefits of reformulating warm-start recommendation problems as extreme multi-label learning tasks by scaling beyond classical recommender systems and achieving prediction accuracy gains of up to 37 %. Furthermore, in a live deployment for sponsored search on Bing, it was observed that SwiftXML could increase the relative click-through-rate by 10 % while simultaneously reducing the bounce rate by 30%. |

|
abstract /
bibtex /
pdf /
code
In this paper, we propose an approach for automatic detection of bike-riders without helmet using surveillance videos in real time. The proposed approach first detects bike riders from surveillance video using background subtraction and object segmentation. Then it determines whether bike-rider is using a helmet or not using visual features and binary classifier. Also, we present a consolidation approach for violation reporting which helps in improving reliability of the proposed approach. In order to evaluate our approach, we have provided a performance comparison of three widely used feature representations namely histogram of oriented gradients (HOG), scale-invariant feature transform (SIFT), and local binary patterns (LBP) for classification. The experimental results show detection accuracy of 93.80% on the real world surveillance data. It has also been shown that proposed approach is computationally less expensive and performs in real-time with a processing time of 11.58 ms per frame. |
|
|
|